

AI Features are shipping. Billing is working. Pricing is set. Then usage creeps, and the questions start.
- How did one user burn through most of the monthly budget for their account?
- Why did this request get blocked while an identical one went through?
- Who's supposed to catch runaway usage before it turns into an outage, or an uncomfortable conversation with an enterprise customer?
This isn't a product gap or a billing bug. At scale, AI usage management becomes a hard infrastructure problem, and none of the systems teams already rely on were built to solve it. Your enterprise customers want more than reports. They want control. Limits, allocations, budgets for predictable behavior as usage scales.
This post explains why a dedicated control layer is critical for usage management, and why most teams only discover that need once it is already painful.
The stack underneath AI usage
Most engineering teams build these layers incrementally, and each one introduces a harder problem than the last.
Pricing - Defines how you package and sell AI capabilities through tiers and quotas. It sets the potential for margins, but does not protect them. The challenge is mapping pricing to real cost drivers like tokens, requests, or model usage, otherwise you risk selling plans that look profitable but leak margin with every call.
Billing - Turns usage into revenue through subscriptions and invoicing. It improves revenue capture, but still operates after the fact. The engineering challenge is correctness and lifecycle handling, but the business limitation is that billing cannot prevent losses, it can only report on them once they already happened.
Usage Consumption - Introduces real-time metering and limit enforcement, which is the first step toward protecting margins. By tracking and gating usage as it happens, you reduce uncontrolled consumption. The challenge is handling high-throughput events, bursty AI workloads, and enforcing limits with low latency and strong consistency.
Credits - Adds a controlled spending mechanism by turning usage into a consumable balance. This directly improves margin predictability by forcing prepayment or bounded usage. The challenge is building a reliable distributed accounting system with atomic deductions, expiration logic, and no double-spending under concurrency.
AI Usage Management - Enables allocations, budgets, and real-time control across users, teams, and models. This is where margins are actively protected and optimized. Instead of just limiting usage, you can shape it by prioritizing workloads, capping exposure, and aligning consumption with business value. The engineering challenge is making fast, distributed decisions in the request path, forecasting usage, and preventing runaway costs without degrading the product experience.
Most teams have the first two layers covered. Some have the third. Very few have built the last two with the reliability and scale that AI-driven workloads actually demand. That's where the problems begin.
.png)
The problem shows up in production
When AI usage starts growing, it rarely triggers an immediate failure. The system drifts into a state where behavior becomes hard to predict.
Limits exist, but it's unclear which ones apply. Credits exist, but ownership is fuzzy. Budgets exist, but enforcement happens too late to matter. Engineering teams start seeing symptoms before they see the root cause.
Usage spikes that can't be attributed to a single user or request. Inconsistent blocking where similar calls produce different outcomes. Manual overrides to unblock customers, followed by cleanup nobody asked for.
None of this feels like a pricing problem. It feels like the system is missing a decision point.
AI-driven workloads change the shape of consumption in ways traditional systems weren't designed for. Requests are bursty and often machine-generated. A single user action can fan out into dozens of downstream operations, each consuming from shared resources. Under load, multiple requests can hit the same limits simultaneously.
Why billing systems cannot enforce usage
This is where most teams hit a hard boundary.
Billing systems are designed to process usage after execution. They collect events, aggregate consumption, and produce accurate financial outcomes. That decoupling from runtime behavior is intentional. It's what makes billing systems reliable and auditable.
Usage enforcement requires the opposite. It has to sit directly on the execution path. It needs request context, low latency, and deterministic behavior under concurrency. It needs to answer a yes or no question in milliseconds, not reconcile numbers hours later.
When teams push enforcement into billing or reporting systems, the compensating behavior starts immediately. Guards get added to individual services. Limits get duplicated. Logic drifts. Over time, control becomes fragmented and increasingly brittle.
The issue isn't that billing systems are being misused. It's that they are solving a fundamentally different problem. A usage control layer has to be designed from the start to sit in front of execution, not behind it.
Limits, allocations, and budgeting at enterprise scale
Once usage becomes something the system must actively decide on, limits stop being simple counters.
In enterprise contexts, budgets and limits are defined across organizational structure: teams, business units, environments, and sometimes regions, all typically drawing from the same underlying pool. A business unit may have 1 million AI tokens or a $50,000 budget allocated, subdivided across departments and individual users, each with their own seat-type specific limits.
This multi-dimensional structure has to be modeled explicitly.
Resource Types:
{
"resourceTypes": [
{
"id": "org",
"name": "Organization",
"properties": {
"displayName": { "type": "STRING", "required": true }
}
},
{ "id": "dept", ... },
{ "id": "team", ... },
{
"id": "user",
"name": "User",
"parentResourceTypeId": "team",
"properties": {
"email": { "type": "STRING", "required": false },
"tier": { "type": "ENUM", "values": ["STANDARD", "PREMIUM"], "required": true }
}
}
]
}
List of resources:
{
"resources": [
{
"id": "org-acme",
"resourceTypeId": "org",
"customerId": "cust-acme-inc",
"properties": { "displayName": "Acme Org" }
},
{ "id": "dept-marketing", ... },
{ "id": "team-growth", ... },
{
"id": "user-alice",
"resourceTypeId": "user",
"parentResourceId": "team-growth",
"customerId": "cust-acme-inc",
"properties": { "email": "alice@acme.com", "tier": "STANDARD" }
},
{ "id": "user-bob", ... }
]
}
Resource-level allocations:
{
"allocations": [
{
"resourceId": "org-acme",
"creditCurrency": "ai-tokens",
"customerId": "cust-acme-inc",
"limit": 50000,
"enforcementType": "HARD"
},
{ "resourceId": "dept-marketing", ... },
{ "resourceId": "team-growth", ... },
{
"resourceId": "user-bob",
"creditCurrency": "ai-tokens",
"customerId": "cust-acme-inc",
"limit": 200
}
]
}A single request may touch multiple dimensions simultaneously: the user making the request, the team or org they belong to, the feature being invoked, and the shared credit pool backing all of it. At runtime, the system has to answer a simple question: is this request allowed? But answering it correctly requires resolving all applicable limits consistently, under concurrency, and with low latency:
const entitlement = await stigg.getCreditEntitlement({
resourceIds: ['user-01', 'emea', 'engineering'],
creditCurrency: 'ai-tokens',
options: { requestedUsage: estimatedCredits },
});
if (!entitlement.hasAccess) {
return entitlement.accessDeniedReason;
}
// 3. Has enough credits, execute the AI operation
// ...
Each entitlement check is then followed by actual usage reporting:
// 1. Execute the AI operation
// ...
// 2. Emit a usage event with resource attribution
await stigg.reportEvent({
customerId: 'test-customer-id',
eventName: 'email_enrichment',
idempotencyKey: '227c1b73-883a-...',
dimensions: {
user_id: 'user-01',
region: 'emea',
org: 'engineering'
},
timestamp: '2025-10-26T15:01:55.768Z'
});
Even at modest scale, 5 products, 10 features, 50 teams, the number of possible limit combinations exceeds 2,500. At enterprise scale, that reaches tens of thousands. Consider 20 teams making 1,000 requests per minute across 10 features: that's 200,000 requests per minute, each requiring multi-dimensional limit resolution in near real time.
This is not just a modeling problem. It is a concurrency problem.
Consumption under load: concurrency, consistency, and correctness
Under real workloads, multiple requests will attempt to consume from the same pool at the same time. If enforcement isn't consistent, one of two outcomes follows: limits are exceeded silently, or legitimate requests are blocked incorrectly. Both erode trust: with engineering leadership, with customers, and with finance.
Common approaches borrowed from billing systems don't hold up here:
- Webhooks introduce latency and failure points. Even a small failure rate produces incorrect enforcement at scale.
- Polling creates stale data or infrastructure overload. Sub-second intervals would be needed to maintain accuracy, and even then correctness during bursts can't be guaranteed.
Enforcement has to live as close to execution as possible. For that, Stigg built a solution to be as close as possible to the source.
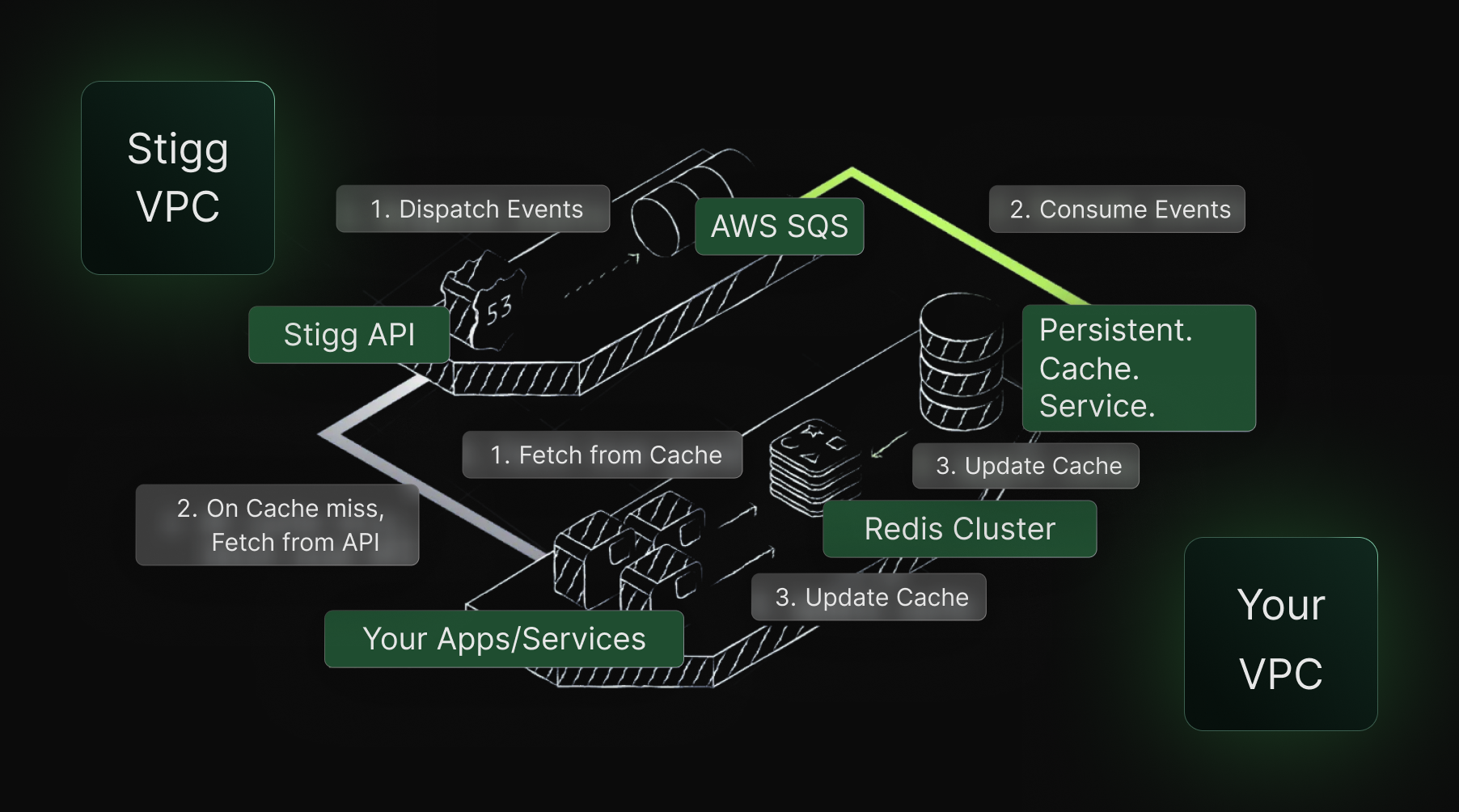
Read more on Stigg's Sidecar and Sidecar SDK. The control layer isn't a reporting function. It's an infrastructure function, and it has to be designed as one.
Enforcement must happen as usage occurs
AI-driven workloads are bursty, parallel, and often fully automated. By the time asynchronous systems observe consumption, the moment to enforce has already passed.
This is where most teams underestimate the scope of the problem. Balancing latency, correctness, and scale under concurrent load is a genuinely hard systems challenge. It requires careful tradeoffs around consistency models, failure handling, and concurrency primitives. Traditional billing and reporting systems were not designed for this role and will not grow into it.
For a deeper dive into the practical tradeoffs involved in enforcing credits and usage at scale, see this writeup on building AI credits and why enforcing them correctly was harder than expected.
Control without visibility isn't control
Enterprise customers expect to manage AI usage the same way they manage their organization: consumption, limits, and remaining budgets visible at the levels where decisions are actually made: individual users, teams, departments, and organizational totals.
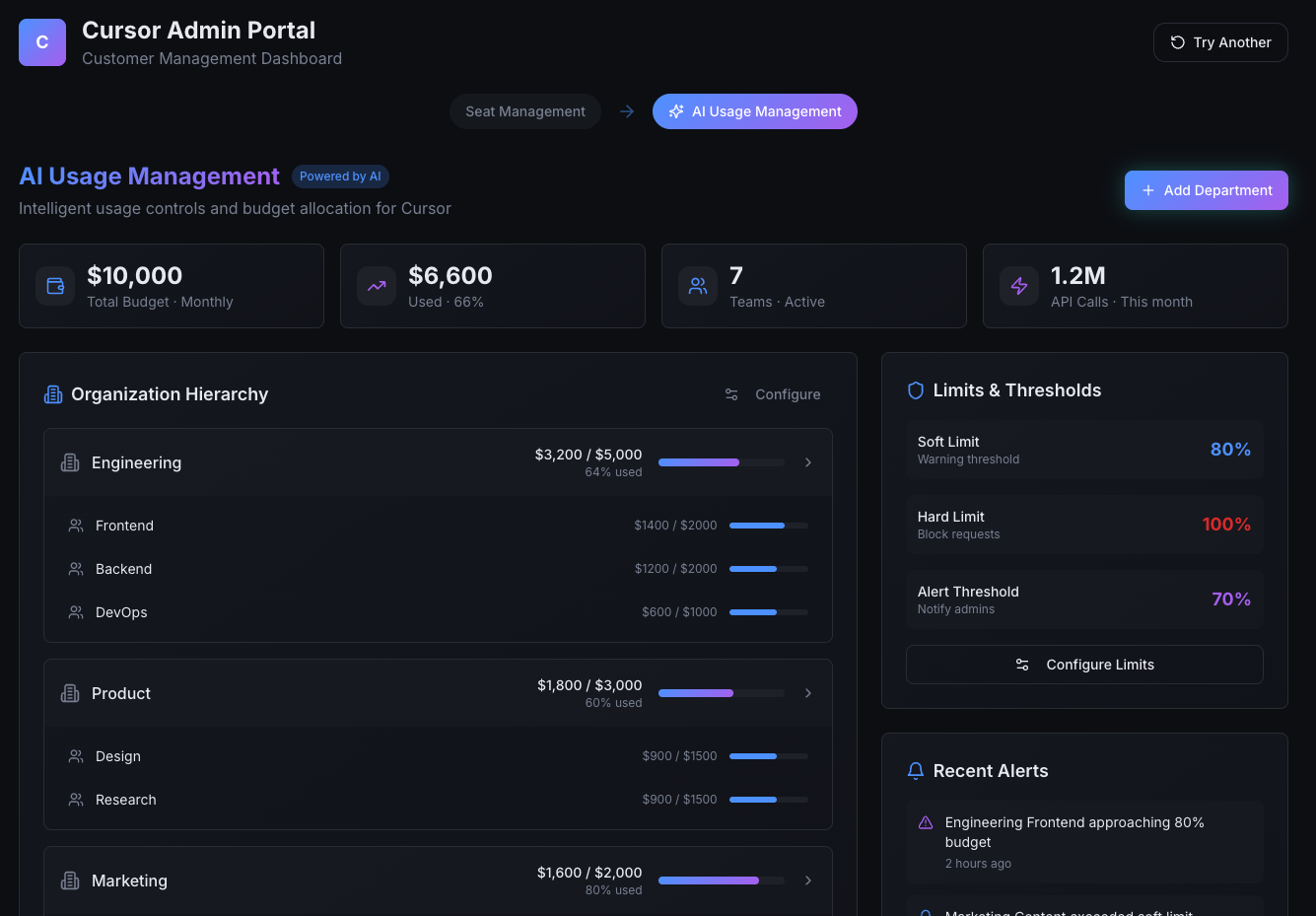
This isn't a reporting requirement. It's a trust requirement. If customers can't clearly explain their own usage pattern, they won't trust the system, even if billing is technically correct. Usage data must be explainable, not just accurate.
Embedding a usage management interface directly into your product removes the entire support burden:
import { UsageManagementPortal } from '@stigg/react-sdk';
export default function AIGovernancePage() {
const { user, organization } = useCurrentUser();
const isAdmin = user.role === 'admin';
return (
<div className="admin-page">
<StiggProvider apiKey="CLIENT_API_KEY" customerId={organization.id}>
<UsageManagementPortal
rootResourceId={organization.id}
creditCurrency="ai-credits"
readOnly={!isAdmin}
/>
</StiggProvider>
</div>
);
}
Why usage management is replacing user management
"When software is consumed by automated pipelines instead of people, identity alone is no longer a sufficient control surface."
Traditional SaaS access control was built around identity. You granted or denied access based on who was asking. Seats were the primary unit of control.
AI changes this model fundamentally.
What matters isn't who is calling the system. It's how much is being consumed, by which part of the organization, under what constraints, and right now.
Usage management becomes the new control layer because it answers a different question entirely: what can be consumed right now, and should it be allowed?
This shift is explored further in When Your Customer Is an Algorithm, which explains why automated consumption breaks traditional pricing assumptions and pushes control into runtime systems.
Most production AI systems today are still missing this layer. Without it, usage stays reactive, enforcement happens too late, and every new AI feature or enterprise deal adds more surface area to an already fragile control model. The teams that get ahead of it build it as infrastructure, before production forces their hand.
.png)


