"Premature optimization is the root of all evil" -Donald Knuth
For a startup with limited resources, balancing immediate functionality and long-term product viability is essential. Stigg is no different, and when faced with the challenge of handling migrations for millions of customer subscriptions, our first priority was a robust and scalable foundation with core features that bring immediate value.
Then, came the customers. And as our customer base grew, the initial pipeline reached its limit. So yes, for a while we could keep optimizing it, but after squeezing every drop of performance we decided to re-evaluate, re-build, and re-optimize for our growing scale.
This post will show you how we rebuilt one of our core systems: entitlement calculation and subscription migration. In it, we’ll talk about different caching strategies, cache invalidation, and dynamic vs pre-calculated data. We will then show how Stigg manages it for our customers, each of whom has millions of customers of their own.
Stigg is an infrastructure that allows its customers to manage pricing and packaging for their customers. To avoid confusion, in this article we’ll refer to Stigg's customers as “vendors”, and their customers as “customers”.
But before we do, let’s talk a bit about subscription migration in general, and why we need it.
Pricing Modeling
Pricing and packaging are complicated! Every company that looks to price its products and services competitively enters a world of business strategies, user personas, legacy considerations, and competitive research insights. It’s common to see competitors with similar products implement different pricing and packaging strategies, and leveraging them as a differentiator.
Pricing and packaging is usually reflected to customers in “pricing tables” with tiers that are tailored to specific market segments.
As your product evolves and you cater to more customer segments, pricing and packaging can be become mightily complicated. For example, Zapier’s pricing which has 5 plans, 4 of which are offered via self-service:
You can also check our pricing quest to see how top tier companies have evolved their pricing over the years.
Subscription migration
Applying changes to pricing and packaging is a must as your product evolves and in order to stay ahead of your competition. Luckily, Stigg makes publishing of such changes easy - you can choose whether to roll out the changes only to new subscriptions, thereby grandfathering existing subscriptions, or to apply them to existing ones as well. Applying changes to existing subscriptions, triggers a migration that updates their entitlements.
A subscription migration is the process which ensures that customers receive the latest entitlements they deserve when a change is rolled out to existing subscriptions.
Calculating Entitlements
In essence, entitlements are a set of permissions defining what a customer (paying or non-paying) can do with your software application. For example, an entitlement can grant the customer access to the “Audit logs” feature or limit their account to “5 seats” within a given plan. Entitlements Untangled, by Anton Zagrebelny
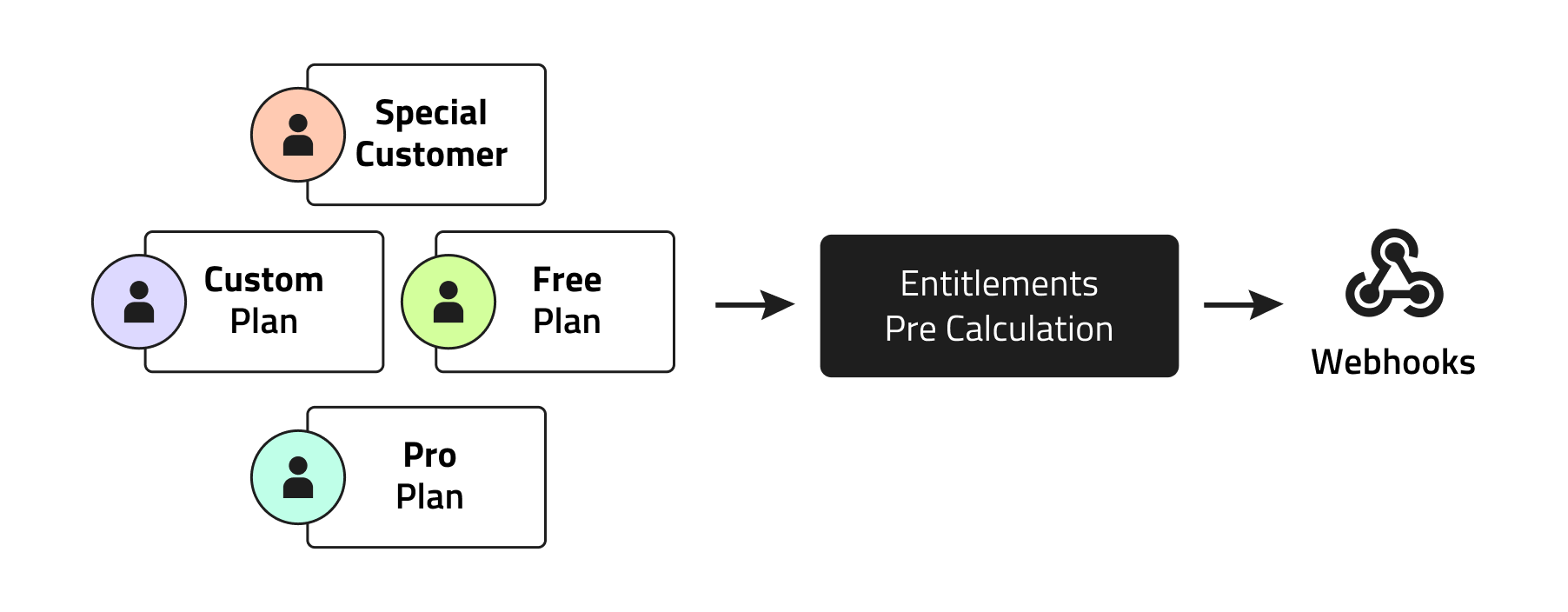
Resolving customers' entitlements collection can be complicated. They can, and usually do, come from multiple sources: the purchased plan, parent plans, add-ons, promotions, custom entitlements, and more.
On top of that, Stigg allows its vendors to create multiple subscription of the same product, as well as a global subscription that controls entitlements across the account. For example, Auth0 has a global plan granting global entitlements, and then a subscription per tenant that controls a specific tenants’ resources. Read more about how Stigg handles multiple subscriptions here.
At Stigg, we provide our customers with a highly available, scalable and fast infrastructure, resolving customer's entitlements and serving them in under 100ms, while providing smart caching options to reduce recurring requests to a few milliseconds.
Pre-Calculation vs Dynamic Calculation
When we first implemented entitlement calculations, the need to balance functionality with future-proofing nudged us in the direction of pre-calculation. Essentially, every time a customer’s plan or add-on changes, we recalculate their entitlements and store them in multiple AWS regions. That way, the edge API can fetch and serve them blazingly fast. No calculation was performed at the edge.
As with everything pre-calculated, scale is your enemy. Updating entitlements for 10K customers? Sure. But what happens when a vendor, who has millions of customers, performs a small change in their free plan? It’s not pretty. With all of these subscriptions changing, their entitlements need to be recalculated, and a lot of DynamoDB records need updating.
This flow in the middle? It happens for every subscription
The impact of such a change creates two problems: time and cost.
Time-wise - each entitlement calculation can take a few milliseconds. At a large enough scale, we’re looking at hours of calculations that can’t be completely mitigated by throwing more compute power at the tasks. Bottlenecks can include database CPUs, SNS rate limits, DynamoDB write limits, and more.
All of this didn’t matter much when we were just getting started, but as we began to onboard larger vendors, each with millions of customers, seeing migrations that take a long time to complete while putting a constant load on our platform, we decided it was time for a paradigm shift.
Then there’s the cost impact, it’s important to understand that DynamoDB focuses on expensive writes and cheap reads, and with multiple regions requiring updates, every write operation becomes even more costly.
You should also keep in mind that if a vendor has a free tier, changing its entitlements will incur costs for customers who don’t bring in any money. With an average paid-to-free ratio of about 1/100, which is very popular at self-served SaaS, that’s quite a lot of compute resources spent on non-paying customers.
Stigg Goes Dynamic
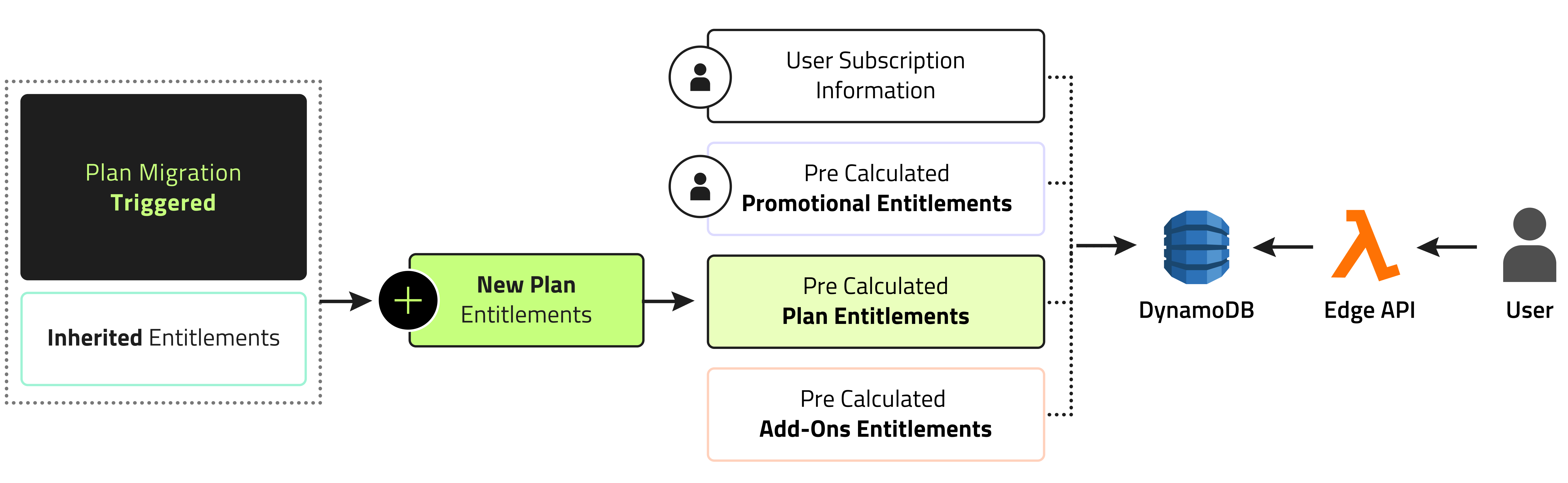
Considering the fact that Stigg allows vendors to make frequent changes to their pricing, and with the realization that pre-calculation for every entitlement no longer being feasible, we decided to start calculating them on the fly. Simply put, we save only the building blocks of a customers’ entitlements, update those blocks as needed, and combine them in real time when asked by the edge API to provide the entitlement collection.
As you can see in the diagram, instead of storing a customers’ entitlements we only store their subscription information, which isn’t bound to change as frequently. Separately, we store pre-calculated entitlements from plans, add-ons, and promotions. A change to these, however frequent, no longer require millions of writes.
Now, all the edge API needs to do is fetch the customer's subscription, use it to collect their entitlements, and concatenate these into a single response.
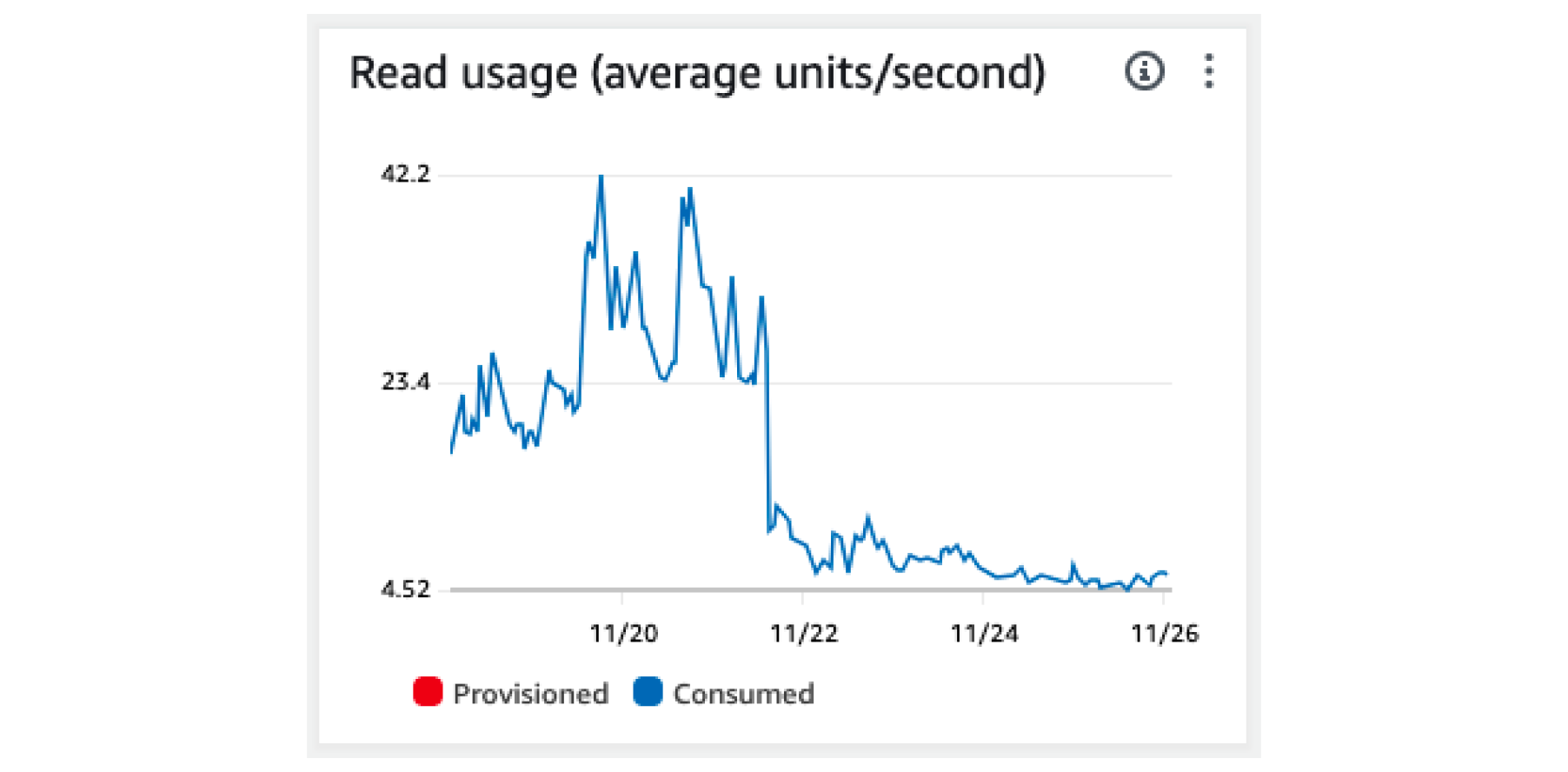
We’ve then implemented smart caching on the edge, in order to store plans and add-ons on the Lambdas. That way, we don’t even need to fetch them from DynamoDB, allowing us to keep the same blazing-fast level of service while keeping read costs low.
DynamoDB read before and after adding edge caching
So now, whenever a plan migration is triggered, we only need to recalculate its entitlements, update DynamoDB, and that's it - customers will automatically receive the updated entitlements.
New Solution, New Problems
As with all things software-related, every solution is a compromise. So far, we've mostly talked about out edge storage and compute, but what about our persistency layer? At Stigg, we use Postgres to store most of our data, and whenever we publish a new plan, we need to update all of the subscription records in our relational DB as well. To stay below CPU limits, we these update in batches, at a constant rate of 3 million records per second per migration. This allows us to run migrations for multiple customers at once, without affecting one another, while maintaining high throughput for all of them.
Now, you might have noticed another slight difference between the pre-calculated and dynamically calculated drawings: the disappearance of cache and webhooks. That’s because another compromise we had to make is in our approach to the services that actually need pre-calculated entitlements.
In the old pipeline, since we've been recalculating entitlements for all of our customers, it was easy to just send <span class="fira-code">entitlement.updated </span> events with the new entitlements. It was also easy to push the newly updated entitlements directly to the customers’ in-memory and Redis-based cache, managed by our SDK and persistent cache service, so that our vendors could serve their customers within milliseconds.
In the new pipeline that's more complicated. We've decided to split this problem into two parts: cache invalidation and webhooks.
Cache invalidation: as mentioned, our vendors use in-memory and Redis based cache to improve latency serving their customers. Once a migration is triggered, this data becomes stale. In the new pipeline, instead of pushing the new entitlements, we've decided to send "invalidation signals" which contain chunks of affected customers, and then gradually replace stale data with fresh one fetched from the edge API. Due to the fact those signals are very small, invalidation takes places instantly, allowing our vendors to also serve updated entitlements instantly from their cache.
Webhooks: this is even trickier! Our customers rely on webhooks to update systems such as CRMs, data warehouses, etc. <span class="fira-code">entitlement.updated </span> events are a crucial part of this process, which means we have no choice but to perform some sort of pre-calculation to send those events downstream.
We've decided to detach this process from the core migration. This way, we can handle those events without impacting the migration.
In order to perform as few calculations as possible, we look at the target audience of a migration and split it into similar groups. For example, since all free plan subscriptions receive the same entitlements, why bother recalculating them? We calculate them once and send those webhooks events for all free customers. We repeat this process with every plan, as long as those customers don't have any overrides that can affect their entitlements - add-ons, promotions, etc.
The Bottom Line
Rethinking the pipeline was an awesome challenge, but let’s not forget, our main goal was to hit performance goals while improving customer experience and ensuring Stigg’s scalability for the foreseeable future. How did we do on those fronts? Let’s see!
Time-wise, we've improved migration time roughly 100X, going from an average migrate rate of 200K subscriptions per hour to 20M subscription per hour.
Cost-wise, DynamoDB is the main resource used in migration and accounts for 50% of our cloud cost. By moving away from write-intense to read-intense operations and considering the fact that we only read active customers’ information, we've removed almost all of our DynamoDB cost, resulting in a 50% reduction of our monthly bill.
That reduction, by the way, didn’t just come from DynamoDB, but also from hundreds of Lambda compute hours we did away with as they were no longer needed. And while compute is relatively cheap, it’s still nice to reduce your reliance on paid services.
Now that our infrastructure is more efficient and scalable than ever, I have absolutely no qualms about saying the following: whoever you are, however big your business is, we have the resources to provide you with an awesome headless pricing and packaging infrastructure. So sign up for a free Stigg account and come see what we’re all about!







.png)
.png)