Best practices I wish we knew when integrating Stripe webhooks
In this article we will describe what are the best practices to create the webhook integration with Stripe. We will be focusing only on one side of our two-way integration. The side that is listening to webhooks and acting on them.
Why are we so obsessed with Stripe incoming webhooks in Stigg?
One of the value propositions of our product is our no-code Stripe integration. When integrating with Stigg we take care of everything related to interacting with Stripe for our customers. We sync all the plans and add-ons, customers, and subscriptions and manage the state of those entities in Stigg and propagate changes to Stripe if needed. We are also listening to webhooks from Stripe that indicate that something changed to the synced entities on Stripe's side.
One of the most important flows in Stigg is the Create Subscription flow. When having a Stripe integration and a paid subscription is created we are waiting for an incoming webhook from Stripe to acknowledge that the payment was successfully made in order to make the subscription active. Failing to create subscriptions for any reason can lead to our customers losing money and therefore this has to be a well-tested, highly resilient, and easy to scale.
In this article, we will describe what are the best practices to create the webhook integration with Stripe. We will be focusing only on one side of our two-way integration. The side that is listening to webhooks and acting on them.
What’s the problem with spinning up an API to listen to Stripe webhooks and act on them?
It is fairly easy to just listen to incoming webhooks with a service and act upon them and that's how we started when developing the proof of concept for this feature.
It could be something along those lines:
For us, this was great for the proof of concept but not good enough to go to prod.
There are a few issues with this design that we, in the engineering team, spotted and wanted to address in order to be confident about this new part of the integration:
What happens if we are down and webhooks are not being processed?
What happens if our processing fails silently?
How can we monitor failures properly?
How can we be sure that we can reprocess failed events on our own when we fix a potential bug on our side?
If Stripe bombards us with events, how do we scale our processing speed without losing data?
We had to build something way different to answer these questions. And with the complexity of the design, we found out that there are many caveats in the way Stripe is implementing their webhooks. Some of those limitations we found the hard way, so reading this can actually save you a lot of pain trying to build your webhook integration.
So here are a few limitations we had to take into account when designing the new solution for reliable Stripe webhooks processing and what it meant for us:
“Stripe does not guarantee delivery of events in the order in which they are generated” ~Stripe docs. That means that we need to be very careful processing an event and we can’t rely on a `customer.subscription.created` event to arrive before the `customer.subscription.updated` event. It’s awesome to allow us to process in parallel as much as we want. But really not awesome when we want to first create a subscription and then update it as it happens naturally.
“Webhook endpoints might occasionally receive the same event more than once” ~Stripe docs. This is a good one. Anything you build relying on Stripe webhook has to be Idempotence. Don’t miss this one!
You can’t persist the webhook and reprocess them later. Stripe is limiting us to verify the signature of the webhook within 5 minutes to avoid replay attacks. Failing to do so, will make the event fail with an error. While it increases the security, it doesn’t allow us to propose a design where we persist all webhooks and process them later. It’s not possible because the first step of processing a webhook is unpacking it with `stripe.webhooks.constructEvent` which verifies the signature and would fail if invoked more than 5 minutes after the webhooked arrived.
“Stripe will attempt to notify you of a misconfigured endpoint via email if an endpoint has not responded with a 2xx HTTP status code for multiple days in a row” ~Stripe docs. If webhooks start failing, don’t rely on Stripe to let you know there is an issue. It will take a few days until they will let you know something is off.
We are addressing all the Stripes limitations and our requirements both on the code application level and the way we build our architecture.
How do we mitigate limitations 1 and 2?
We are mitigating those two limitations on the application level and not on architecture level.
Limitation 1: Stripe does not guarantee delivery of events in the order in which they are generated
This is a very interesting topic that caused us quite a lot of trouble in the beginning when we just started. For us, the key was to listen to the right events for different use cases and fetch data from Stripe when missing. Let’s look at a concrete example. When creating a subscription we are listening to a subscription.created event in order to activate a subscription after the payment was successful. We also listen to subscription.updated webhook to sync subscription status. In some cases when we just started we received subscription.updated events before subscription.created events (exactly as Stripe docs are promising).It caused our lambda to start throwing exceptions as the webhooks arrived in the wrong order. The subscription.updated handle expected that we already processed a subscription.created webhook and created a subscription.
The solution for us was to fetch the subscription and create it if it’s not yet created in our database. The code could look something like:
We always keep this limitation in mind when we grow and listen and process more events. We should always think about that in our designs and implementations.
Limitation 2: Webhook endpoints might occasionally receive the same event more than once.
We didn’t experience that one too often but we did build our processing mechanism in a way that we are working in an idempotent manner. We can always run the same message through our system and the result will always be the same.
The last two limitations are mitigated on the infrastructure level and therefore let’s try to get a better understanding of how to design a Stripe webhook integration.
Overview:
AWS API Gateway to take the hit from Stripe.
Lambda function Gateway integration that verifies the signature of the webhooks and persists them on a queue.
AWS SQS with DLQ for reprocessing,
AWS Lambda function that will read and handle the event.
And now let's review each infra item and explain how it answers all our tech requirements.
1. AWS API Gateway to take the hit from Stripe. (limitation 3)
Our requirement here was to build an API to receive the webhooks from Stripe and persist them on a queue without having extra logic that can become a point of failure and process them with a Lambda function later.
We knew that API Gateway has native integrations with SQS (and Lambda).
This wouldn’t be sufficient for us as we had to have some code verifying and constructing the messages at the moment they arrive synchronously (limitation No 3).
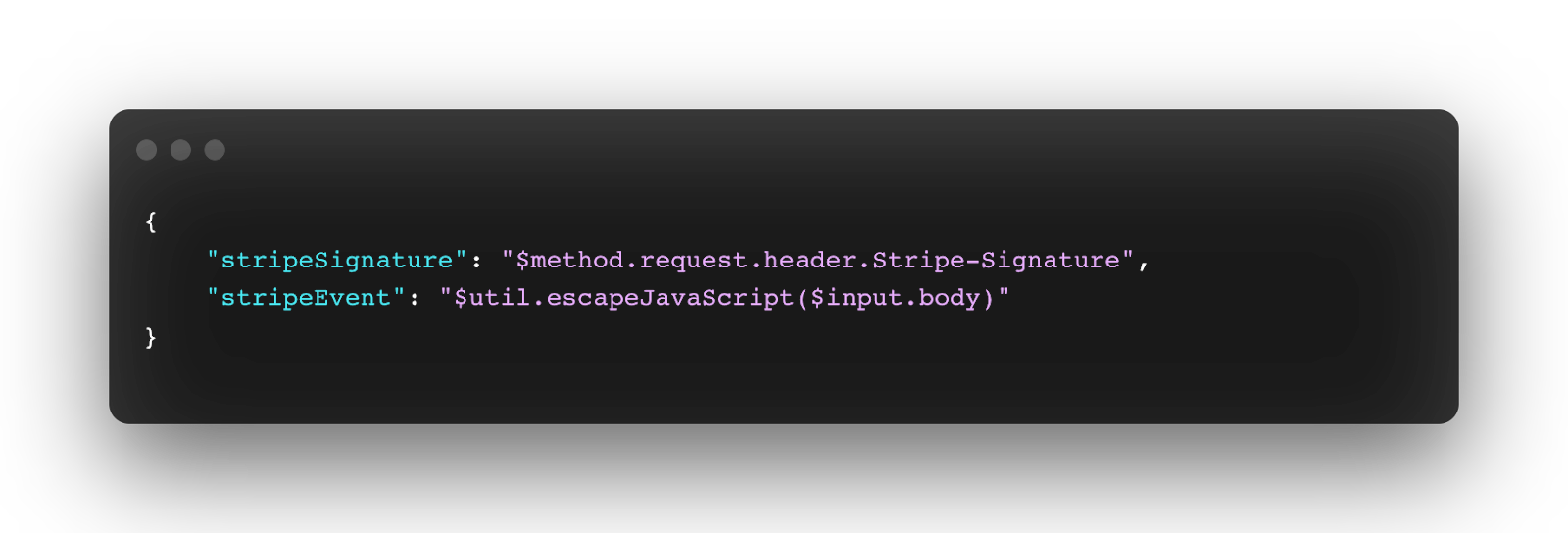
In our implementation, we had to extract the Stripe signature from the headers to use it to verify the event's authenticity and the Stripe event itself. We achieved that by using Mapping Template on the Integration Request. Essentially it allows us to remap the http requests properties to a JSON that would be easily processed by the lambda. In our case, we are mapping the Stripe Signature from the header of the webhook to a stripeSignature parameter and the body of the webhook to a stripeEvent parameter. The mapping code:
2. Lambda function Gateway integration (limitation No 4)
We ended up choosing to have a native API Gateway Lambda integration that would be super simple, doing as little processing as possible. This is important for us as it is the first component that the external stripe webhook hits when entering our cloud. Failing to persist an event here would cause a failure to act upon that webhook and its data will be lost forever.
This mapping code should be planted in the API Gateway in the Integration requests:
Moreover, we are very carefully monitoring this lambda for errors to actively know if we are missing any webhooks immediately. According to limitation No 4, it will take Stripe a few days to let us know if there is a problem with the webhooks. As Stripe webhooks are so crucial to our business, we can’t afford not knowing that something is wrong with them only in a few days.
3. AWS SQS with DLQ for reprocessing
We already rely heavily in Stigg on having SQS with DLQs deployed alongside in order to help us scale quickly and process with multiple lambdas when needed. We also rely on that architecture to automatically retry or manually reprocess messages that have failed after fixing the issue causing the failure.



.png)
.png)



.png)
.png)
.png)

